
궤도
[딥러닝] 밑바닥부터 시작하는 딥러닝 6장 본문
6.1 매개변수 갱신
HyunJiLim0406/Practice
Contribute to HyunJiLim0406/Practice development by creating an account on GitHub.
github.com
확률적 경사 하강법(SGD)
: 미리 정해둔 학습률만큼 이동함. 일정한 방향만 이동하겠다 -> 비등방성 함수에서는 탐색 경로가 비효율적
모멘텀
: v 변수를 추가. 기울기 방향으로 학습률이 가속되도록 조정. 바닥을 구르는 경로 형성
AdaGrad
: 학습률을 점점 낮추는 방법 중 매개변수 '전체'의 학습률 값을 일괄적으로 낮추는 방법
Adam
: 모멘텀 + AdaGrad
문제에 따라 효율적인 갱신 방법은 제각각이기 때문에 상황에 맞춰 적절한 방법을 채택해야 함.
6.2 가중치의 초깃값
HyunJiLim0406/Practice
Contribute to HyunJiLim0406/Practice development by creating an account on GitHub.
github.com
초깃값을 0으로(가중치를 균일한 값으로 설정하는 것) 설정하면 안됨.
왜냐하면 오차역전파법에서 모든 가중치의 값이 똑같이 갱신되기 때문 -> 가중치를 여러 개 갖는 의미 사라짐
=> 그렇기 때문에 초깃값을 무작위로 설정해야 함.
가중치에 따른 활성화값 분포

기울기 소실 문제 발생

활성화값 치우침

가장 나은 모습
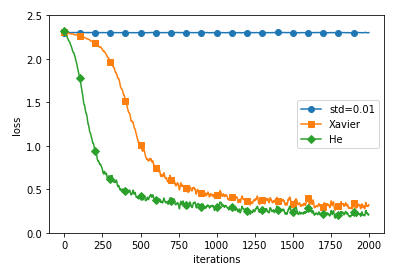
6.3 배치 정규화
초깃값을 적절히 설정해야 활성화값 분포가 적당히 퍼짐
-> 각 층이 활성화를 적당히 퍼뜨리도록 '강제'할 수는 없나? => 배치 정규화
배치 정규화의 특징
- 학습을 빨리 진행할 수 있다.
- 초깃값에 크게 의존하지 않는다.
- 오버피팅을 억제한다.
6.4 바른 학습을 위해
HyunJiLim0406/Practice
Contribute to HyunJiLim0406/Practice development by creating an account on GitHub.
github.com
오버피팅 : 신경망이 훈련 데이터에만 지나치게 적응되어 그 외의 데이터에는 제대로 대응하지 못하는 상태
오버피팅의 경우
- 매개변수가 많고 표현력이 높은 모델
- 훈련 데이터가 적음
가중치 감소
: 학습 과정에서 큰 가중치에 대해 그에 상응하는 큰 페널티를 부과하여 오버피팅을 억제
드롭아웃
: 뉴런을 임의로 삭제하며 학습. but 시험 때는 모든 뉴런에 신호를 전달.
6.5 적절한 하이퍼파라미터 값 찾기
HyunJiLim0406/Practice
Contribute to HyunJiLim0406/Practice development by creating an account on GitHub.
github.com
하이퍼파라미터 : 각 층의 뉴런 수, 배치 크기, 매개변수 갱신 시의 학습률과 가중치 감소 등
지금까지의 사용 데이터셋 : 훈련 데이터 & 시험 데이터
but 하이퍼파라미터의 성능을 평가할 때는 시험 데이터 사용불가 => 검증 데이터 사용
하이퍼파라미터 최적화 하는 방법
- 0단계 하이퍼파라미터 값의 범위를 설정
- 1단계 설정된 범위에서 하이퍼파라미터의 값을 무작위로 추출
- 2단계 1단계에서 샘플링한 하이퍼파라미터 값을 사용하여 학습하고, 검증 데이터로 정확도를 평가
- 3단계 1단계와 2단계를 특정 횟수 반복하며, 그 정확도의 결과를 보고 하이퍼파라미터의 범위를 좁힘



